teste !
Reuniões
1-Mar-24
YOLOv9 paper released on 21FEV24
- yolov9 + atrativo
- meter v9 a funcionar na maquina ciafa
- o q é q vamos ganhar em relação ao v8 ?
- perceber se v9 serve os nossos prpopositos ?
- exemplo minimo a correr no ciafa
- adotar escrito para tese
8-Mar-24
- 03-Mar-24: eu percebi q estava a ser parvo quando disse "ah e tal o yolov9 n tem segmentação ainda, então talvez seja melhor ficar com o yolov8"
- para fazer o autolabelling nós apenas precisamos das capacidades do YOLO para fazer object detection, e por sua vez as "bounding boxes", portanto dá para usar YOLOv9
22-Mar-24
- equilibrio entre quantidade e qualidade de images
- selecionar datasets com o mais parecido com o que temos
- depois do YOLOv9 filtrar a qualidade do q vai para o SAM. basicamente ver se as bounding boxes estão boas para ir para o SAM e excluir o que tá errado
- ver ferramenta de anotação do roboflow para segmentação (Human annotator)
- unified dataset:
- prioridade UAV/aereo,
- identificar um test set de apenas imagens aereas anotadas e q não estejam no treino
- identificar outro test set com imagens genericas/ground anotadas sem estar no train set
- meter tb falso negativo
- treino pode ter coisas que não são aereo florestal
- ~1000 test set (aéreas) (linha 7)
- ~1000 test set + x (linha 8)
- datasets com frames fazer uma amostragem
- weights and biases
26-Apr-24
- ver anchors do yolov9 (?)
- ver configuaração que possa limitar tamanho de bounding box
- "As for bounding box size constraints, there isn't a direct built-in feature in YOLOv8 to limit detection by minimum or maximum bounding box size during the post-processing steps. However, it is a reasonable feature consideration for quality control in certain applications, and we may consider such additions for future versions." source
- passar pipeline na dataset LK
- ver yolov8/v9 segmentacao
- criar tabela com parametros do treino (tamanho de imagem, batch size, data augmentation, lr, epocas)
- averiguar val a 0
- guardar configuração do treino
Meeting with Rashmi 27-Apr-24
Meeting
Do you upload your code to benchmarks?
Yes, the code is uploaded to benchmarks, at least we do in MIT. We make our code open source to help other researches and to make our work reproducible.
Info
In papers with code there are multiple researches that upload their code and datasets. MIT and University of S. Francisco does this, but not every company or university does, such as CorsicanFire.
How do you upload? For example, in a benchmark suite like CityScapes it is expected of the researcher to download a training set, develop a model, upload the model/code and then the model is evaluated by the benchmark suite on the backend. In my third challenge I want to give the option to researchers to distribute their code through different hardware, do you know any frameworks where this is possible?
(maybe I didn't make myself very clear here because the answer was not very targeted to the hardware distribution) We usually use Amazon SageMaker 1 and Amazon S3 2 bucket ecosystem. We upload our dataset do S3 bucket and our code to SageMaker. SageMaker is what runs the code files. This is not a free service
Are you familiar with ONNX?
Yes ONNX is heavily used. ONNX is also like a framework/platform is which you can have a checkpoint of a format of your model and then you can convert it to any other framework. For example, you can convert a PyTorch model to a TensorFlow model. ONNX is a very good platform for model conversion. This is called platform agnostic, so you can convert a model from one framework to another.
For edge devices there is also TensorFlow Lite, which is a framework that is used to convert models to be used in edge devices. ONNX is more for cloud computing.
- Look into ONNX
- Look into TensorFlow Lite
Can you elaborate on Amazon Sagemaker? How does it work?
Basically Sagemaker is like when you use Google Colab GPU's. They offer very good GPU's and you can run your code on their GPU's. And S3 is like Google Drive, where you can store your data.
You are explaining how your environment, as a developer/researcher, is right? Regarding to this, I was thinking to create a docker image that has pre-installed all the necessary libraries and frameworks to run the code and to make it compatible with the serverside hardware. Do you think this is a good idea?
Yes docker is actually a good idea. Docker, Kubernetes and all these kind of platform in which you are adding whichever requirements are needed like the Python version, the libraries etc.
Lets imagine that, you as a researcher, want to benchmark a model for fire and smoke segmentation and you come acros with my benchmark online. How would you like/be easier for you to interact with it?
Questão para os orientadores Is it even worth it to continue with the benchmark suite if there is already a popular and trusted platform named Kaggle?
You need the model from the researchers and you will give them a dataset. This is similar to Kaggle competitions.
Unlike Kaggle, I don't know if it is possible to create a public repository where researchers can upload their models (upload the model on Amazon S3).
Are there any free alternatives to Amazon S3 and SageMaker?
Maybe Google Drive but that wouldnt be very efficient would it?
Me: I'm concerned about the size of the models if researchers are uploading them via Google Drive and also the privacy problems they might have on Google/Amazon services.
Then, the best option would have to be a local server right? Does your university have a server that you can use?
To create the benchmark suite I was thinking to code a full stack application made with NuxtJS and Flask. Do you think this is a good idea?
You would have problems with the storing of the models. You cant store them in, for example, a MySQL database because of the size. You would have to store them, either locally on the server, or in a cloud service like Amazon S3.
Me: Yes, I think we should store them locally. But we actually, as a benchmark, dont need to store the models and code for that long right? We only need the models to be stored for the time of the evaluation and then we could delete them, right?
Rashmi: Yes, you are right. You only need the models for the evaluation. I think your idea of using Docker images. I'm a bit skeptical for a single person to develop a full stack application like this because its very hard to do. You would normally need a team to do this.
So the whole pipeline for this all it would be: I'm a researcher, I go to the benchmark suite website, I download the Docker image with the pre-defined libraries that need to run on the server-side I would develop my code. I would upload my code and my model and my results, after tested, would be displayed in a table
Yes, it sounds simple but its very complex to implement.
On the third challenge, I'm still not sure how could I make the splitting of the model/code throghout different hardware.
What do you mean by different hardware? There would be hardware constraints?
Me: Yes, a challenge only on a NVIDIA 4090 and another challenge on a NVIDIA Jetson. Then a third challenge where a researcher can split the model across the two hardware.
Rashmi: Do you know the power of a NVIDIA Jetson? I'm not sure if it's capable of image processing. They can't process heavy images. What would be the size of the images? Are you aware about all these specs?
Me: I'm not sure about what hardware I will use. I know for a fact that I want to make a benchmark for normal GPU's, for edge devices and for a combination of both. What I was asked was to create a dataset for a benchmark suite, and I've been given a bunch of images, some labeled and some not. Then I should preform all the labelling on the images and create a unified dataset. The images I've been given are SUPER random, from frames of a video to aerial images to ground images, images from fireman, images from the web. The size of the images also differs a lot.
Rashmi: The image size for researchers is very important. There are images with 15MB and images with 2GB, and you can imagine that you cant process accurately a 2GB image in a model trained with 15MB images.
It's crucial to consider the resources available to researchers. Sometimes, they might not have the means to train models or build them from scratch. From my perspective as an evaluator, I'll be assessing their models and benchmarking them. But it's important for researchers to also think about building their own models. (pelo contexto acho que ela estava a falar sobre a necessidade de nos preocuparmos com os recursos em termos de hardware dos investigadores, mas não percebi muito bem. Os pesos não iriam ser os mesmos se o código e dataset fosse o mesmo?)
When discussing the dataset with your professor, consider what it will look like and what hardware resources you'll have access to. This information will be essential for building the front-end application. For instance, if you're planning to create a user interface with upload buttons, you need to know what kind of hardware you'll be working with.
If you're dealing with multiple hardware options, things can get tricky. Not all hardware supports inference. For example, while we might use Amazon SageMaker for training models due to its capabilities, we often resort to EC2 instances for inference because they're more cost-effective.
So, it's crucial to clarify the hardware resources available, the nature and size of the dataset, and then devise a plan for the full-stack architecture. Given the constraints and costs associated with various platforms like S3, SageMaker, Google Cloud, or Azure, it seems like building a custom full-stack application tailored to your specific needs is the best approach.
That's just my perspective on you we should proceed.
03-May-24 (Maj. Cruz)
- establecer o tamanho de imagens da dataset
- o trabalho dos investigadores no nosso caso tb é tratar dos dados
- o que é que a NVIDIA tem para converter um modelo para um edge device
- começar a escrever o que já foi feito no autolabelling
- descrever o processo de autolabelling
- explicar o YOLOv9 e SAM genericamente
- explicar as configurações de cada e explicar o output e input de cada
- criar diagramas a explicar (talvez)
- marcar reuniao c prof. Bernardino
uma ideia por paragrafo
Sobre as datasets:
- fazer 2 grupos: imagens limpas e imagens contaminadas
- organizar por tamanho de imagem
- marcas de agua
- fazer estatisticas (tipo qual % de imagens tem marca de agua)
06-May-24 (Prof. Bernardino)
O que foi feito até agora:
- Autolabelling tool
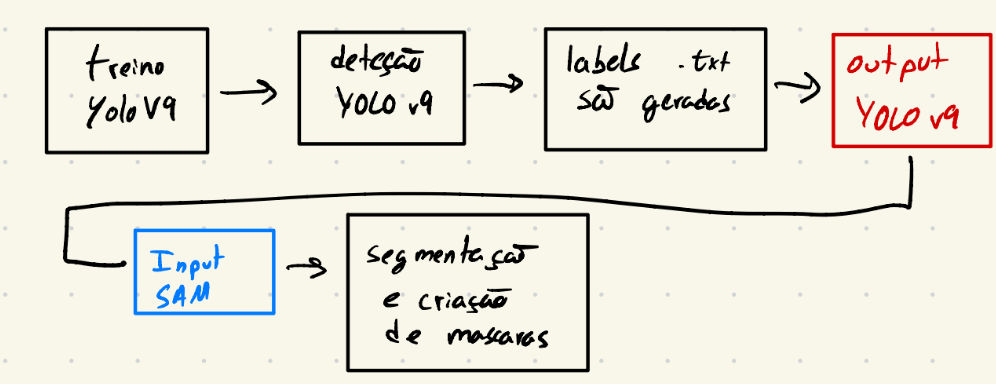
-
Mostrar resultados da autolabelling tool
-
Ferramenta para organizar as imagens, ver aqui e talvez mostrar. Github
- Reunião com investigadora afiliada do MIT para perceber +- como é que eles fazem as coisas
Problemas a discutir:
- Tamanho das imagens
- não é problema
- Qualidade das imagens, ou seja, se é para contar com imagens contaminadas (marca de agua, imagens com baixa qualidade, etc)
- R não meter water marks no test set
- damos tudo aos investigadores, mas na test set queremos aproximar o máximo à realidade
- focar em deteção de fogo e fumo aérea
- não usar HH_Gestosa_Fire_Segmentation na training set, é uma boa dataset para test set
- fazer crop das imagens da HH_Gestosa_Fire_Segmentation par anão apanhar o aviao
- ver as especificações da dataset, camara usada etc
- Qual é o hardware que temos disponível
- jetson edge
- Como é que posso melhorar o YOLOv9 para o nosso caso de uso
- experimentar modelo de segmentacao do YOLOv9 piores resultados
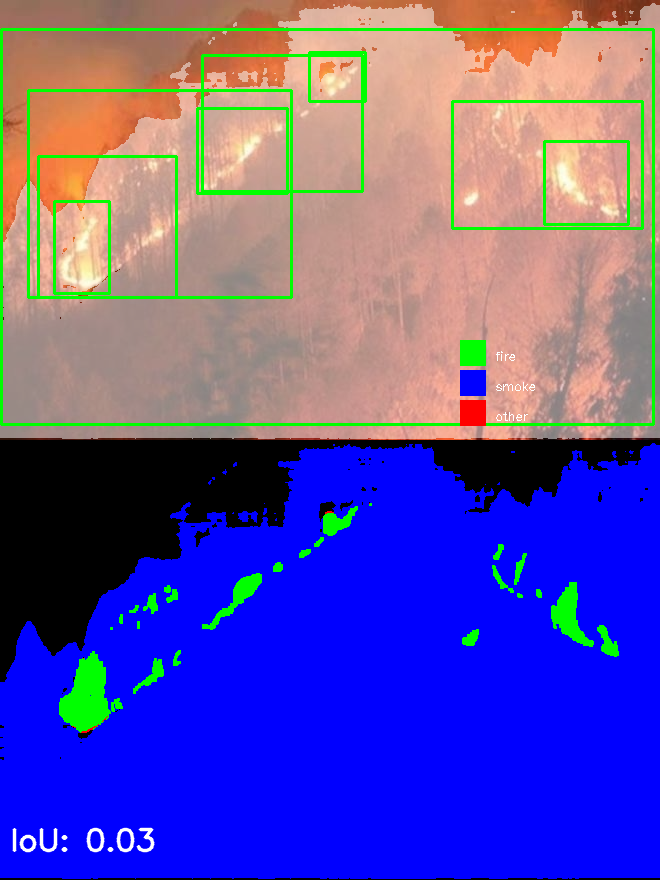
- IoU médio para a dataset GP_Fire_Segmentation_Webimages_v1 é de 0.52
- IoU médio para a dataset HH_Gestosa_Fire_Segmentation é de 0.00 -> YOLO não detetou nada.
- Problemas do YOLOv9: falsos negativos, bounding boxes muito grandes
- Existe maneira de diminuir as bounding boxes? (pelo que estive a ver nos issues do github do YOLOv8 não está implementada uma função do tipo)
- Tenho duvidas sobre a segmentaçao de fumo por parte do SAM
- fazer analise qualitativa, mostrar a varias pessoas a mesma segmentacao e perceber se elas concordam com a segmentação. Labels da Lisa têm dois graus, ambiguo e nao ambiguo
- É possivel ter uma maquina remota do IST? Estou a usar uma da AFA e às vezes tenho problemas
Melhores 5 imagens da dataset GP_Fire_Segmentation_Webimages_v1





Piores 5 imagens



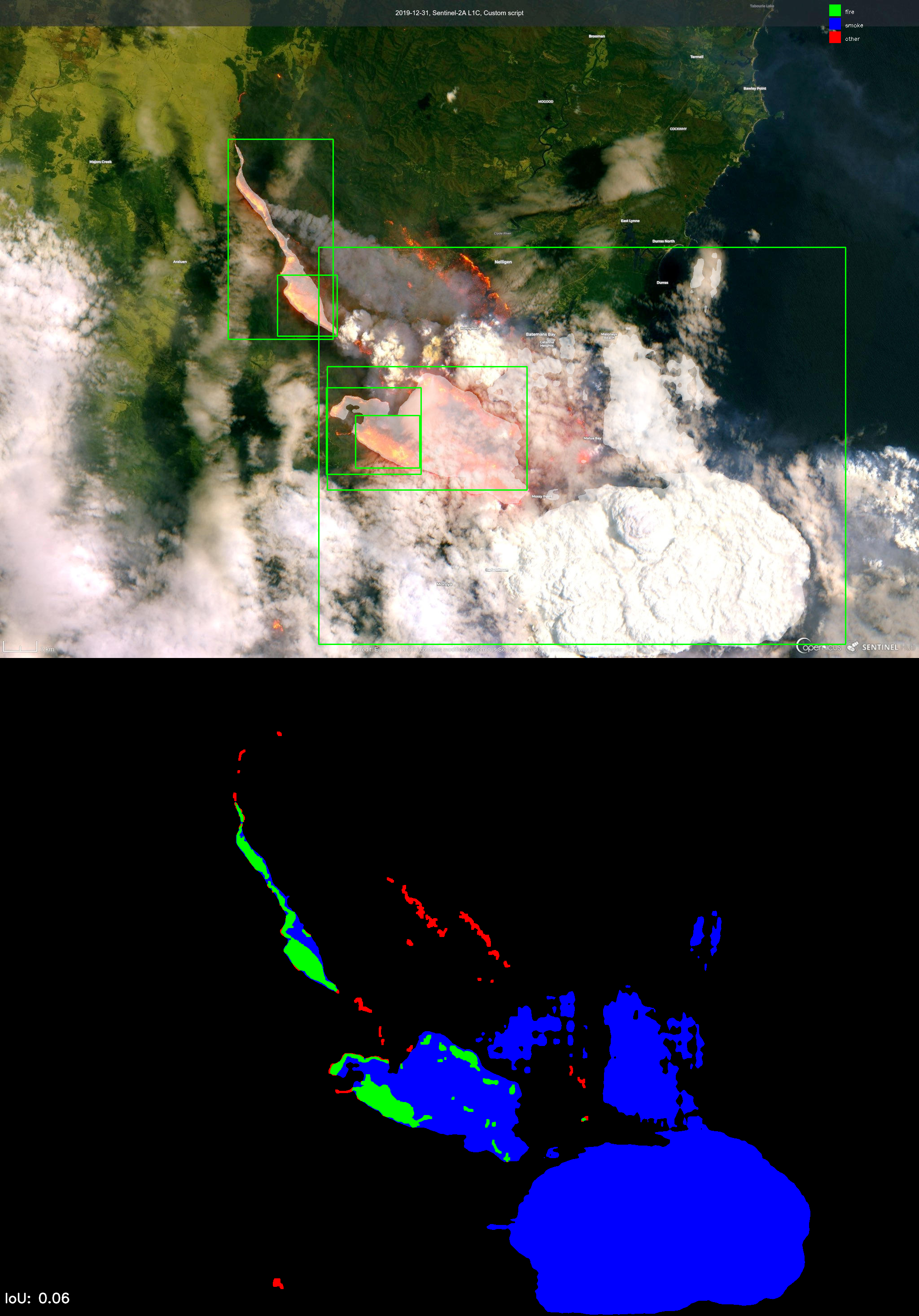
09-May-24 (Maj. Cruz)
Trabalho realizado esta semana:
- Avaliar se o YOLOv9-seg é melhor que a pipeline YOLOv9-det + SAM
- treinado um modelo YOLOv9-seg com uma dataset com 201 imagens (foi o que encontrei preparado para YOLOv9…), o YOLOv9-det foi treinado com 8939…
- retreinar com nova dataset com 6k images, para ser mais justo
- Avaliado modelo treinado YOLOv9-det 8k images 100 epochs, para várias datasets, IoU subiu
- Detetado erro quando passagem da pipeline pela dataset HH_Gestosa, IoU está agora nos 0.4 relativamente à ground truth
- Passagem da pipeline pela LK_Fire com modelos diferentes, resultados parecem bons
Duvidas:
- Ainda é possivel arranjar fotos da FAP?
Trabalho Futuro:
- Treinar YOLOv9-seg com 3k images
- Ver se é melhor que a pipeline: não é melhor
- Escrever sobre resultados: a escrever, ainda falta comparação entre pipeline e YOLOv9-seg
Resultados:
| Dataset | Model | Method | mean IoU |
|---|---|---|---|
| GP_Fire_Segmentation_Webimages_v1 | fire_best | pipeline | 0.52 |
| GP_Fire_Segmentation_Webimages_v1 | 5_out | pipeline | 0.53 |
| LK_Fire+Smoke_V1 | fire_best | pipeline | no label |
| LK_Fire+Smoke_V1 | 5_out | pipeline | no label |
| HH_Gestosa_Fire_Segmentation | 5_out | pipeline | 0.4 |
| GP_Fire_Segmentation_Webimages_v1 | results_100 | yolov9-seg | 0.3 |
| GP_Fire_Segmentation_Webimages_v1 | results_200 | yolov9-seg | 0.33 |
13-May-24 (trabalho)
- treinar YOLOv9-seg com 3k images 10 epochs
- treinar YOLOv9-seg com 3k images 50 epochs
- escrever sobre resultados
- mandar mail ao Cmdt 991
- pensar na forma de organizar as fotos
- conversão entre máscaras PB e label txt YOLOv9
- esta conversão só será útil para retreinar o yolov9 com as imagens que são anotadas pelo ser humano. para isto tenho de ponderar deixar a autolabeling OU arranjar uma forma de passar da máscara para uma label txt de bounding box (o que eu acho que é muito muito mais complexo)!
23-May-24
Trabalho realizado:
- Pedido de fotos à Esq. 991 -> perguntei ao Ten. Luís Santos informalmente se a esquadra tinha fotos, e ele disse que sim, porém que devia contactar o Cmdt.
- Pedido formal Sr. Gen. CEMFA
- Treino YOLOv9-seg
- 10 epochs
- 3k images
- 50 epochs
- 3k images
- 100 epochs
- 200 images
- 3k images
- 200 epochs
- 200 images
- 10 epochs
- Começar escrita
Resultados YOLOv9-seg:
| Model | IoU |
|---|---|
| 10_epoch_model_3k | 0.4048 |
| 50_epoch_model_3k | 0.429 |
| 100_epoch_model_200 | 0.307 |
| 100_epoch_model_3k | 0.429 |
| 200_epoch_model | 0.334 |
Imagens


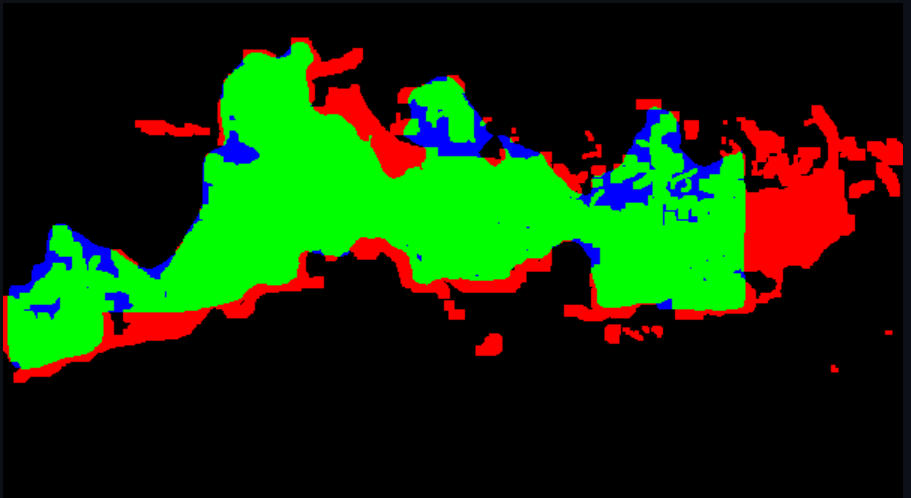
Trabalho futuro:
- escrever sobre resultados do YOLOv9-seg
- criar script para transformar mascaras PB em label txt YOLOv9, para retreinar
- treinar novo modelo com as imagens que já tenho label
- começar a fazer a label das imagens
- criar script para separar as imagens que são aceites e as que não são aceites pelo anotador (tipo, um script que mostre as imagens, as imagens com a deteção do YOLOv9 e as mascaras de segmentação. Depois o anotador só tem de premir uma tecla para decidir se passa ou não. Caso passe, a imagem e a sua respetiva label é automaticamente movida para a pasta final da unified dataset, caso não passe, a imagem é automaticamente movida para uma pasta de imagens não aceites. Depois desta passagem, retreinar o YOLOv9 novamente com as imagens que foram aceites. Repetir o processo até temros as imagens todas labeled)
Duvidas:
- Imagens CA
- Pq é q não é boa ideia pedir imagens à 991? (o pedido já seguiu porque já tinha falado com o DC sobre isso)
- ter imagens que não são acessiveis ao publico, ou seja, as que forem cedidas pela 991/CA são uma otima fonte para o test set que irá estar no server side
- Perante os resultados, deixo o YOLOv9-seg e foco apenas na pipeline (YOLOv9-det+SAM)? Relembrar que o YOLOv9-det foi treinado com 6k imagens, e o YOLOv9-seg com 3k imagens. Também seria muito mais fácil (ainda não sei porque ainda não pensei sobre este assunto a fundo) passar as mascaras PB para o YOLOv9-seg visto que aquilo guarda a posição dos pixeis, facilmente retirada de uma imagem, enquanto que o YOLOv9-det são coordenadas normalizadas
xyhw.
06-Jun-24 (Maj. Cruz)
Trabalho realizado:
- Unified dataset (HL_firefront)
- Hypertune de parametros
- Modelo escolhido: 20_ABR_conf_20 -> aumentar a conf threshold melhorou alguns casos das bbox serem mt grandes. mIoU de 0.456.
- Comecei a ver a parte do backend e do frontend.
- Fazer alterações ao LaTeX apontadas pelo Major
Trabalho futuro:
- Fazer programa que mostra as imagens originais e as labels feitas pela pipeline. Utilizador pode descartar a anotação ou pode aceitar. As que forem descartadas, quero integrar a lib do labelme no python para que se possa desenhar poligonos onde a anotação não for boa. Para isto tb tenho de arranjar maneira de passar de mascara B&W para formato labelme, para aproveitar alguma coisa que esteja bem da pipeline e fazer alterações minimas.
Duvidas/Dificuldades:
- Fiquei "vidrado" no treino de hypertunning de parametros perdendo algum tempo que podia ter canalizado para o avanço da pipeline e/ou da fullstack application.
- Ns se já mostrei o "Image Organizer", mas ainda n avancei muito com aquilo. Estão separadas apenas 2000/7500.
- Imagens 991/CA
-
tentar guardar a penultima epoca
- desdobrar o trabalho futuro em dois
- labelme é um nice to have
- pensar como é que os utilizadores vao submeter
- focar na app
- nas mascaras de segmentação ter duas cores para classes diferentes
- pensar em propsota de uniformização
- ver se mascaras tem 1 ou 3 canais (0,128,255)
Latex: - explicar como é que o yolov9 se encaixa na pipeline - revisao literatura tenta se dizer que x metodologia usar y tecnica - falar das adaptacoes que tivemos que fazer para fazer a pipeline
21-Jun-24 (Prof. Bernardino + Maj. Cruz)
Notas da reunião:
- dividir ground/aerial
- mudar cor da mascara do fumo
- não anotar à mao as rejected e retreinar com os accepted
- começar doc de raiz e ir bucar coisas importantes ao pic2
- fazer backend prioritario
- passar unified dataset para segundo plano
- fazer ciclos e mostrar que o modelo melhora
- fazer novo cronograma com perpetiva de evolucao do trabalho sem dependencia de terceiros e mandar para orientadores
- focar na parte do teste
- ver evolucao do modelo à medida que se incrementa a training set problema do tempo aqui, but lets see…
para a semana
- cronograma atualizado
- numeros: imagens com labels: para isto preciso de ter o numero total de imagens, ou seja, faltam as imagens da ESQ991.
- quantas labels é q já tenho feitas
- decisão do que é q vai ser o test set: o test set vai ser composto por cerca de 30%
IMPORTANTE
- Resolver o problema do labelme tirar algumas masks feitas pela pipeline
28-Jun-24
- 6443 FIREFRONT + 534 adquiridas na ESQ.
- perguntar se é para manter
- Labels: 432 + 35 corrigidas = 467 (7.2% | 6.69% c/ 991)
- Test set:
- duas datasets: ground e aereo.
- no test set aereo devem constar imagens do Gestosa e 991, uma vez que são as que mais se aproximam à finalidade do FIREFRONT
15-Jul-24 (prof. Bernardino)
- mascaras morfologica open/close - opencv: para o fogo, delimitar regioes ignore
- dividir bbox para ficarem mais pequenas, ter várias instancias de SAM e fazer a junção para ignorar o erro
- substituir gaussian blur por tela preta
- disponibilizar apenas uma imagem da esq 991 para investigadores terem em conta as caixas pretas e asa do aviao da gestosa
- codigo de pre-processamento e pós deve ser feito dentro de uma layer (para simplificar uniformizacao onnx)
- averiguar diferentes sizes de imagem e uso de onnx